When the decisions of ML models impact people, one should expect explanations to offer the strongest guarantees of rigor. However, the most popular XAI approaches offer none.
The societal and economic significance of machine learning (ML) cannot be overstated, with many remarkable advances made in recent years. However, the operation of complex ML models is most often inscrutable, with the consequence that decisions taken by ML models cannot be fathomed by human decision makers. It is therefore of importance to devise automated approaches to explain the predictions made by complex ML models. This is the main motivation for eXplainable AI (XAI). Explanations thus serve to build trust, but also to debug complex systems of AI. Furthermore, in situations where decisions of ML models impact people, one should expect explanations to offer the strongest guarantees of rigor.
However, the most popular XAI approaches3,23,30,31,33 offer no guarantees of rigor. Unsurprisingly, a number of works have demonstrated several misconceptions of informal approaches to XAI.13,16,25 In contrast to informal XAI, formal explainability offers a logic-based, model-precise approach for computing explanations.18 Although formal explainability also exhibits a number of drawbacks, including the computational complexity of logic-based reasoning, there has been continued progress since its inception.24,26
Among the existing informal approaches to XAI, the use of Shapley values as a mechanism for feature attribution is arguably the best-known. Shapley values34 were originally proposed in the context of game theory, but have found a wealth of application domains.32 More importantly, for more than two decades, Shapley values have been proposed in the context of explaining the decisions of complex ML models,7,21,23,37,38 with their use in XAI being referred to as SHAP scores. The importance of SHAP scores for explainability is illustrated by the massive impact of tools like SHAP,23 including many recent uses that have a direct influence on human beings (see Huang and Marques-Silva13 for some recent references).
Due to their computational complexity, the exact computation of SHAP scores has not been studied in practice. Hence, it is unclear how good existing approximate solutions are, with a well-known example being SHAP.5,22,23 Recent work1 proposed a polynomial-time algorithm for computing SHAP scores in the case of classifiers represented by deterministic decomposable boolean circuits. As a result, and for one concrete family of classifiers, it became possible to compare the estimates of tools such as SHAP23 with those obtained with exact algorithms. Furthermore, since SHAP scores aim to measure the relative importance of features, a natural question is whether the relative importance of features obtained with SHAP scores can indeed be trusted. Given that the definition of SHAP scores lacks a formal justification, one may naturally question how reliable those scores are. Evidently, if the relative order of features dictated by SHAP scores can be proved inadequate, then the use of SHAP scores ought to be deemed unworthy of trust.
A number of earlier works reported practical problems with explainability approaches that use SHAP scores20 (Huang and Marques-Silva13 covers a number of additional references). However, these works focus on practical tools, which approximate SHAP scores, but do not investigate the possible existence of fundamental limitations with the existing definitions of SHAP scores. In contrast with these other works, this article exhibits simple classifiers for which relative feature importance obtained with SHAP scores provides misleading information, in that features that bear no significance for a prediction can be deemed more important, in terms of SHAP scores, than features that bear some significance for the same prediction. The importance of this article’s results, and of the identified limitations of SHAP scores, should be assessed in light of the fast-growing uses of explainability solutions in domains that directly impact human beings, for example, medical diagnostic applications, especially when the vast majority of such uses build on SHAP scores.a
Key Insights
■
Shapley values find extensive uses in explaining machine learning models and serve to assign importance to the features of the model.
■
Shapley values for explainability also find ever-increasing uses in high-risk and safety-critical domains, for example, medical diagnosis.
■
This article proves that the existing definition of Shapley values for explainability can produce misleading information regarding feature importance, and so can induce human decision-makers in error.
The article starts by introducing the notation and definitions used throughout as well as two example decision trees. Afterwards, the paper presents a brief introduction to formal explanations and adversarial examples11 along with the concepts of relevancy/irrelevancy, which have been studied in logic-based abduction since the mid 1990s.10 The article then overviews SHAP scores and illustrates their computation for the running examples. This will serve to show that SHAP scores can provide misleading information regarding relative feature importance. To conclude, we extend further the negative results regarding the inadequacy of using SHAP scores for feature attribution in XAI and briefly summarize our main results.
Definitions
Throughout the article, we adopt the notation and the definitions introduced in earlier work, namely Marques-Silva24,26 and Arenas et al.1
Classification problems. A classification problem is defined on a set of features , and a set of classes . Each feature takes values from a domain . Domains can be ordinal (for example, real- or integer-valued) or categorical. Feature space is defined by the cartesian product of the domains of the features: . A classifier computes a (non-constant) classification function:b . A classifier is associated with a tuple . For the purposes of this article, we restrict the features’ domains to be discrete. This restriction does not in any way impact the validity of our results.
Given a classifier , and a point , with and , is referred to as an instance (or sample). An explanation problem is associated with a tuple . Thus, represents a concrete point in feature space, whereas represents an arbitrary point in feature space.
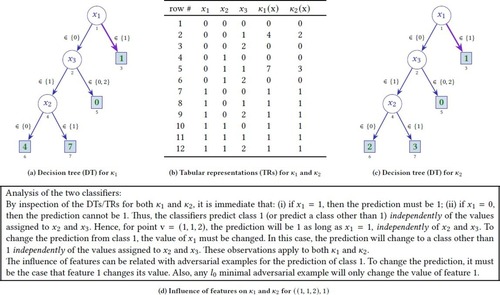
Running examples. The two decision trees (DTs) shown in Figures 1a and 1c represent the running examples used throughout the article. A tabular representation of the two DTs is depicted in Figure 1b. A classification function is associated with the first DT and a classification function is associated with the second DT. Given the information shown in the DT, we have that , , , , and , but some classes are not used by some of the DTs. Throughout the article, we consider exclusively the instance . Figure 1d discusses the role of each feature in predicting class 1, and in predicting some other class. As argued, for predicting class 1, only the value of feature 1 matters. For predicting a class other than 1, only the value of feature 1 matters. Clearly, the values of the other features matter to decide which actual class other than 1 is picked. However, given the target instance, our focus is to explain the predicted class 1.
Figure 1. Decision trees and their tabular representations. For these two classifiers, we have , , and , , and , albeit the DTs and TRs only use a subset of the classes. Literals in the DTs are represented with set notation, to enable more compact DTs. The classification functions are given by the decision trees, or alternatively by the tabular representations. The instance considered is , which is consistent with the highlighted path in both DTs. The prediction is 1, as indicated in terminal node 3.
Figure 1. Decision trees and their tabular representations. For these two classifiers, we have , , and , , and , albeit the DTs and TRs only use a subset of the classes. Literals in the DTs are represented with set notation, to enable more compact DTs. The classification functions are given by the decision trees, or alternatively by the tabular representations. The instance considered is , which is consistent with the highlighted path in both DTs. The prediction is 1, as indicated in terminal node 3.
The remainder of the article answers the following questions regarding the instance . How does the intuitive analysis of Figure 1d relate with formal explanations? How does it relate with adversarial examples? How does it relate with SHAP scores? What can be said about the relative feature importance determined by SHAP scores? For the two fairly similar DTs, and given the specific instance considered, are there observable differences in the computed explanations, adversarial examples and SHAP scores? Are there observable differences, between the two DTs, regarding relative feature importance as determined by SHAP scores?
A hypothetical scenario. To motivate the analysis of the classifiers in Figure 1, we consider the following hypothetical scenario.c A small college aims to predict the number of extra-curricular activities of each of its students, where this number can be between 0 and 7. Let feature 1 represent whether the student is an honors student (0 for no, and 1 for yes). Let feature 2 represent where the student originates from an urban/non-urban household (0 for non-urban, and 1 for urban). Finally, let feature 3 represent whether the student’s field of study is humanities, arts or sciences (0 for humanities, 1 for arts and 2 for sciences). Thus, the target instance denotes an honors student from an urban household, studying sciences, for whom the predicted number of extra-curricular activities is 1.
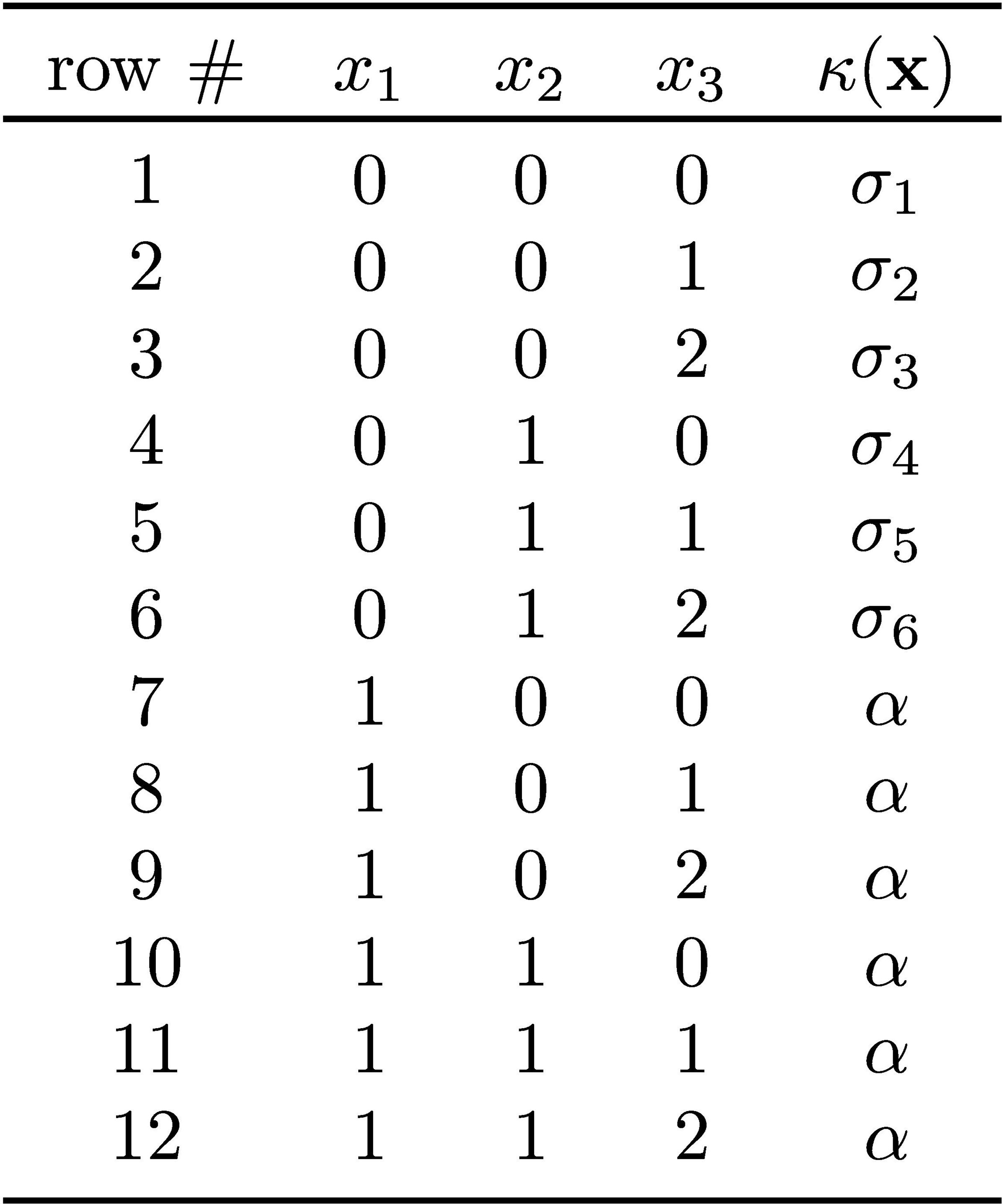
Parameterized example. In the following sections, we consider a more general parameterized classifier, shown in Table 1, which encompasses the two classifiers shown in Figure 1. As clarified below, we impose that,
(1)
For simplicity, we also require that . It is plain that the DT of Figure 1a is a concrete instantiation of the parameterized classifier shown in Table 1, by setting , , and . For the parameterized example, the instance to be considered is .
Table 1. Tabular representation of parameterized classifier,
Table 1. Tabular representation of parameterized classifier,
Formal Explanations and Adversarial Examples
Formal explanations. We follow recent accounts of formal explainability.24 In the context of XAI, abductive explanations (AXps) have been studied since 2018.18,35 Similar to other heuristic approaches, for example, Anchors,31 abductive explanations are an example of explainability by feature selection, that is, a subset of features is selected as the explanation. AXps represent a rigorous example of explainability by feature selection, and can be viewed as the answer to a “Why (the prediction, given)?” question. An AXp is defined as a subset-minimal (or irreducible) set of features such that the features in are sufficient for the prediction. This is to say that, if the features in are fixed to the values determined by , then the prediction is guaranteed to be . The sufficiency for the prediction can be stated formally:
(2)
For simplicity, we associate a predicate (that is, weak AXp) with (2), such that holds if and only if (2) holds.
Observe that (2) is monotone on ,24 and so the two conditions for a set to be an AXp (that is, sufficiency for prediction and subset-minimality), can be stated as follows:
(3)
A predicate is associated with (3), such that holds true if and only if (3) holds true.d
An AXp can be interpreted as a logic rule of the form:
(4)
where . It should be noted that informal XAI methods have also proposed the use of IF-THEN rules31 which, in the case of Anchors31 may or may not be sound.16,18 In contrast, rules obtained from AXps are logically sound.
Moreover, contrastive explanations (CXps) represent a type of explanation that differs from AXps, in that CXps answer a “Why Not (some other prediction, given)?” question.17,28 Given a set , sufficiency for changing the prediction can be stated formally:
(5)
A CXp is a subset-minimal set of features which, if allowed to take a value other than the value determined by , then the prediction can be changed by choosing suitable values to those features. As shown, and for simplicity, we associate a predicate (that is, weak CXp) with (5), such that holds if and only if (5) holds.
Similarly to the case of AXps, for CXps (5) is monotone on , and so the two conditions (sufficiency for changing the prediction and subset-minimality) can be stated formally as follows:
(6)
A predicate is associated with (6), such that holds true if and only if (6) holds true.
Algorithms for computing AXps and CXps for different families of classifiers have been proposed in recent years (Marques-Silva26 provides a recent account of the progress observed in computing formal explanations). These algorithms include the use of automated reasoners (for example, SAT, SMT or MILP solvers), or dedicated algorithms for families of classifiers for which computing one explanation is tractable.
Given an explanation problem , the sets of AXps and CXps are represented by:
(7)
(8)
For example, represents the set of all logic rules (of the type of rule (4)) that predict , which are consistent with , and which are irreducible (that is, no literal can be discarded).
Furthermore, it has been proved17 that (i) a set is an AXp if and only if it is a minimal hitting set (MHS) of the set of CXps; and (ii) a set is a CXp if and only if it is an MHS of the set of AXps. This property is referred to as MHS duality, and can be traced back to the seminal work of R. Reiter29 in model-based diagnosis. Moreover, MHS duality has been shown to be instrumental for the enumeration of AXps and CXps, but also for answering other explainability queries.24 Formal explainability has made significant progress in recent years, covering a wide range of topics of research.24,26
Feature (ir)relevancy. Given (7) and (8), we can aggregate the features that occur in AXps and CXps:
(9)
Moreover, MHS duality between the sets of AXps and CXps allows one to prove that: . Hence, we just refer to as the set of features that are contained in some AXp (or CXp).
A feature is relevant if it is contained in some AXp, that is, ; otherwise it is irrelevant, that is, .e A feature that occurs in all AXps is referred to as necessary. We will use the predicate to denote that feature is relevant, and predicate to denote that feature is irrelevant.
Relevant and irrelevant features provide a coarse-grained characterization of feature importance, in that irrelevant features play no role whatsoever in prediction sufficiency. In fact, the following logic statement is true iff is an irrelevant feature:
(10)
The logic statement here clearly states that, if we fix the values of the features identified by any AXp then, no matter the value picked for feature , the prediction is guaranteed to be . The bottom line is that an irrelevant feature is absolutely unimportant for the prediction, and so there is no reason to include it in a logic rule consistent with the instance.
There are a few notable reasons for why irrelevant features are not considered in explanations. First, one can invoke Occam’s razor (a mainstay of ML4) and argue for simplest (that is, irreducible) explanations. Second, if irreducibility of explanations were not a requirement, then one could claim that a prediction using all the features would suffice, but that is never of interest. Third, the fact that irrelevant features can take any value in their domain without impacting the value of the prediction shows how unimportant those features are.
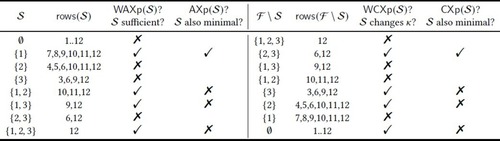
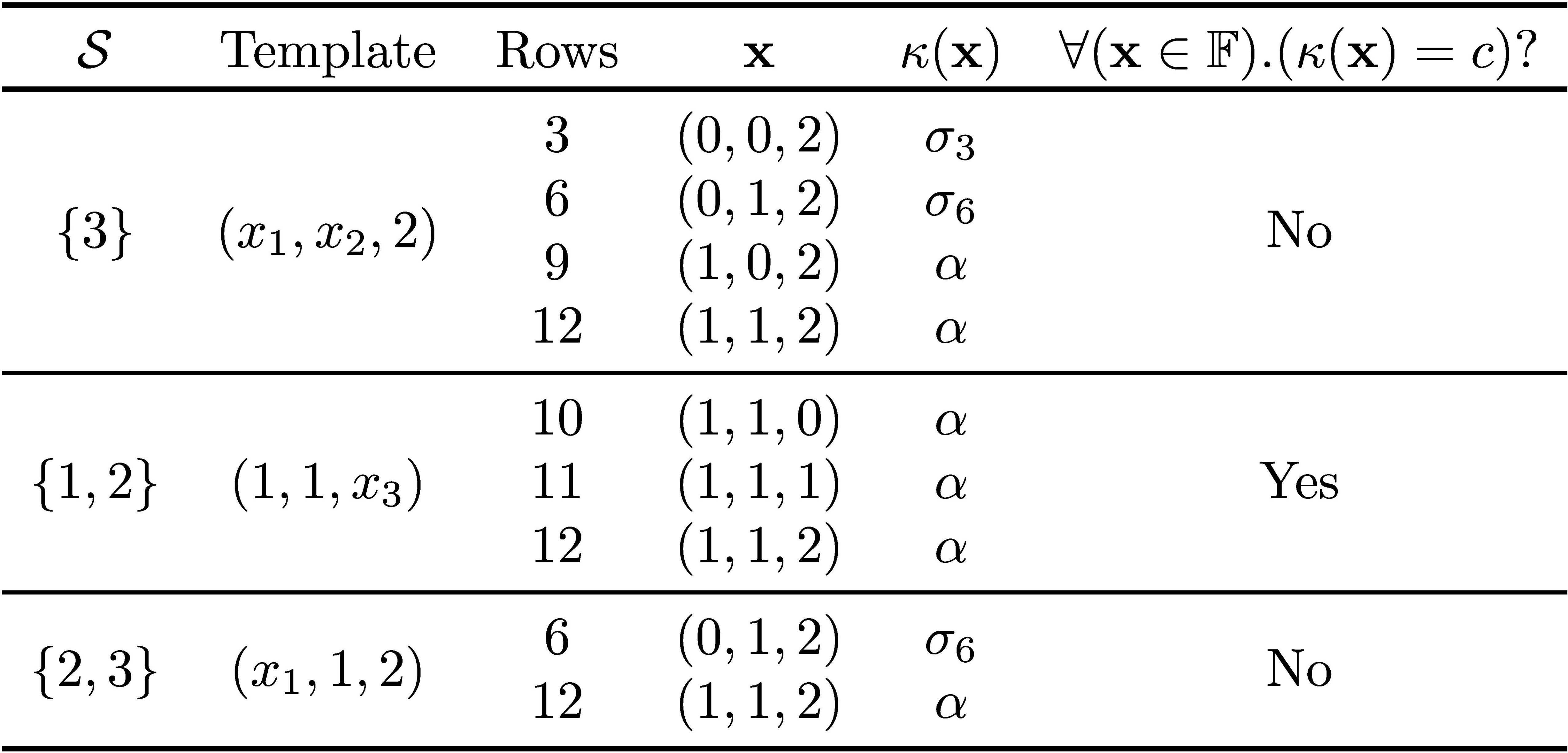
Explanations for running examples. For both the classifiers of Figure 1 or the parameterized classifier of Table 1 (under the stated assumptions), it is simple to show that and that . The computation of AXps/CXps is shown in Figure 2 for the parameterized classifier. More detail on how Figure 2 is obtained is given in Table 2. (Observe that computation of AXps/CXps shown holds as long as differs from each of the , , that is, (1) holds.) Thus, for any of these classifiers, feature 1 is relevant (in fact it is necessary), and features 2 and 3 are irrelevant. These results agree with the analysis of the classifier (see Figure 1d) in terms of feature influence, in that feature 1 occurs in explanations, and features 2 and 3 do not. More importantly, there is no difference in terms of the computed explanations for either or .
Figure 2. Computing AXps/CXps for the example parameterized classifier shown in Table 1 and instance . All subsets of features are considered. For computing AXps/CXps, and for some set , the features in are fixed to their values as determined by . The picked rows, that is, , are the rows consistent with those fixed values.
Figure 2. Computing AXps/CXps for the example parameterized classifier shown in Table 1 and instance . All subsets of features are considered. For computing AXps/CXps, and for some set , the features in are fixed to their values as determined by . The picked rows, that is, , are the rows consistent with those fixed values.
Table 2. Examples of how each set is analyzed when computing AXps. It is assumed that . For CXps, a similar approach is used.
Table 2. Examples of how each set is analyzed when computing AXps. It is assumed that . For CXps, a similar approach is used.
As can be concluded, the computed abductive and contrastive explanations agree with the analysis shown in Figure 1d in terms of feature influence. Indeed, features 2 and 3, which have no influence in determining nor in changing the predicted class 1, are not included in the computed explanations, that is, they are irrelevant. In contrast, feature 1, which is solely responsible for the prediction, is included in the computed explanations, that is, it is relevant. Also unsurprisingly,12,17,19 the existence of adversarial examples is tightly related with CXps, and so indirectly with AXps. These observations should be expected, since abductive explanations are based on logic-based abduction, and so have a precise logic formalization.
Adversarial examples. Besides studying the relationship between SHAP scores and formal explanations, we also study their relationship with adversarial examples in ML models.11
Hamming distance is a measure of distance between points in feature space. The Hamming distance is also referred to as the measure of distance, and it is defined as follows:
(11)
Given a point in feature space, an adversarial example (AE) is some other point in feature space that changes the prediction and such that the measure of distance between the two points is small enough:
(12)
(in our case, we consider solely .)
The relationship between adversarial examples and explanations is well-known.12,17,19
Proposition 1.
If an explanation problem has a CXp , then the classifier on instance has an adversarial example , with .
Similarly, it is straightforward to prove that,
Proposition 2.
If a classifier on instance has an adversarial example with distance that includes an irrelevant feature , then there exists an adversarial example with distance that does not include .
Thus, irrelevant features are not included in subset- (or cardinality-) minimal adversarial examples.
Adversarial examples for running examples. Given the previous discussion, and for , it is plain that there exists an adversarial example with a distance of 1, which consists of changing the value of feature 1 from 1 to 0. This adversarial example is both subset-minimal and cardinality-minimal. As with formal explanations, the minimal adversarial example agrees with the analysis of the two classifiers included in Figure 1d.
SHAP Scores
Shapley values were proposed in the 1950s, in the context of game theory,34 and find a wealth of uses.32 More recently, Shapley values have been extensively used for explaining the predictions of ML models.6,7,21,23,27,36,37,38,39 among a vast number of recent examples (see Huang and Marques-Silva13 for a more comprehensive list of references), and are commonly referred to as SHAP scores.23 SHAP scores represent one example of explainability by feature attribution, that is, some score is assigned to each feature as a form of explanation. Moreover, their complexity has been studied in recent years.1,2,8,9 This section provides a brief overview of how SHAP scores are computed. Throughout, we build on the notation used in recent work,1,2 which builds on the work of Lundberg and Lee.23
Computing SHAP scores. Let be defined by,
(13)
that is, for a given set of features, and parameterized by the point in feature space, denotes all the points in feature space that have in common with the values of the features specified by . Observe that is also used (implicitly) for picking the set of rows we are interested in when computing explanations (see Figure 2).
Also, let be defined by,
(14)
Thus, given a set of features, represents the average value of the classifier over the points of feature space represented by . The formulation presented in earlier work1,2 allows for different input distributions when computing the average values. For the purposes of this article, it suffices to consider solely a uniform input distribution, and so the dependency on the input distribution is not accounted for.
Table 3 illustrates how the average value is computed for two concrete sets of features. As an example, if , then feature 1 is fixed to value 1 (as dictated by ). We then allow all possible assignments to features 2 and 3, thus obtaining,
To compute , we sum up the values of the rows of the truth table indicated by , and divide by the total number of points, which is 6 in this case.
Table 3. Computation of average values. Column ‘Rows’ shows the row numbers in Table 1 to consider when computing the average value.
Table 3. Computation of average values. Column ‘Rows’ shows the row numbers in Table 1 to consider when computing the average value.
To simplify the notation, the following definitions are used,
(15)
(16)
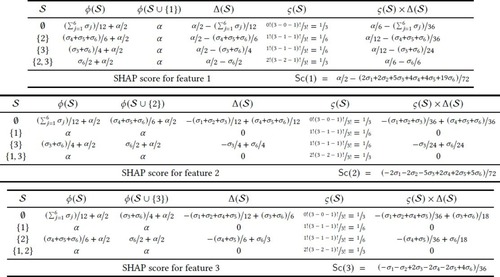
Finally, let , that is, the SHAP score for feature , be defined by,
(17)
Given an instance , the SHAP score assigned to each feature measures the contribution of that feature with respect to the prediction. A positive/negative value indicates that the feature can contribute to changing the prediction, whereas a value of 0 indicates no contribution.37
Misleading SHAP scores. We now demonstrate that there is surprising flexibility in choosing the influence of each feature. Concretely, we want to show that SHAP scores can yield misleading information, and that this is easy to attain. To achieve this goal, we are going to create an evidently disturbing scenario. We are going to assign values to the parameters (that is, classes) of the classifier such that feature 1 will be deemed to have no importance on the prediction, and features 2 and 3 will be deemed to have some importance on the prediction. (Such choice of SHAP scores can only be considered misleading; as argued in Figure 1d, for either or , predicting class 1 or predicting a class other than 1 depends exclusively on feature 1.) To obtain such a choice of SHAP scores, we must have (see Figure 3),
(18)
(19)
(20)
Clearly, there are arbitrarily many assignments to the values of and such that constraints (18), (19), and (20) are satisfied. Indeed, we can express in terms of the other parameters , as follows:
(21)
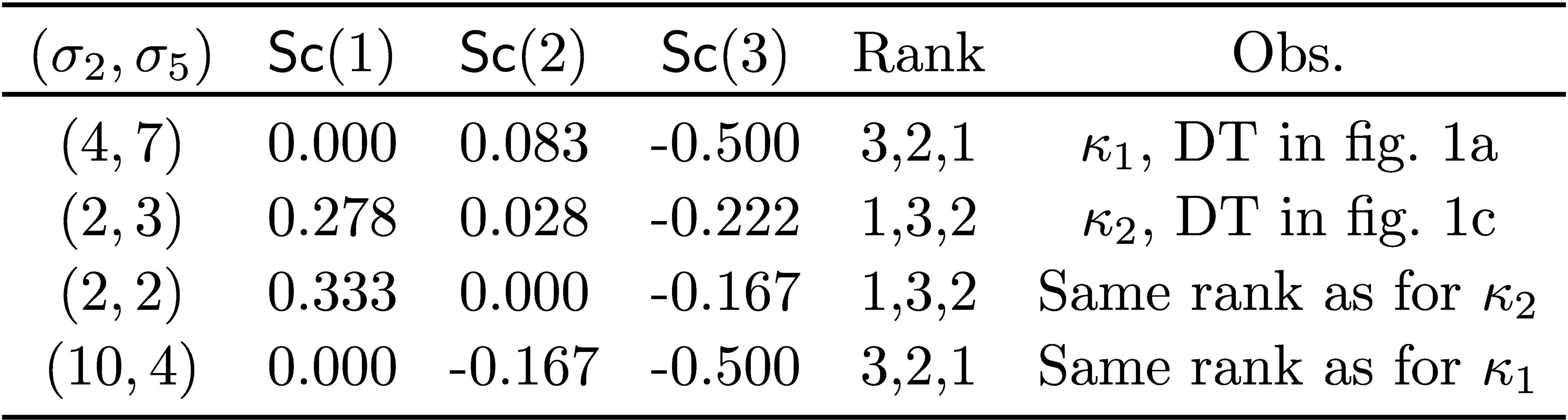
In addition, we can identify values for , , such that the two remaining conditions (19) and (20) are satisfied. Moreover, we can reproduce the values in the DTs shown in Figure 1. Concretely, we pick for both and . Also, for , we choose . Finally, for , we choose . The resulting sets of SHAP scores, among others, are shown in Table 4.
Figure 3. Computation of SHAP scores for the example DT and instance . For each feature , the sets to consider are all the sets that do not include the feature. The average values are obtained by summing up the values of the classifier in the rows consistent with and dividing by the total number of rows.
Figure 3. Computation of SHAP scores for the example DT and instance . For each feature , the sets to consider are all the sets that do not include the feature. The average values are obtained by summing up the values of the classifier in the rows consistent with and dividing by the total number of rows.
Table 4. Computed SHAP scores for the instance , by setting and , that is, DTs similar to those in Figures 1a and 1c, and where only the classes predicted in the terminal nodes 6 and 7 differ.
Table 4. Computed SHAP scores for the instance , by setting and , that is, DTs similar to those in Figures 1a and 1c, and where only the classes predicted in the terminal nodes 6 and 7 differ.
The results derived above confirm that, for the two running examples, in one case the SHAP scores give a rank of the features that must be misleading (that is, Figure 1a), whereas for the other case, the rank of the features is less problematic, in that the most important feature is attributed the highest relative importance (that is, Figure 1c). Evidently, it is still unsettling that for the second DT, the SHAP scores of irrelevant features are non-zero, denoting some importance to the prediction that other ways of analyzing the classifier do not reveal. As the two example DTs demonstrate, and even though their operation is exactly the same when , the predictions made for points in feature space, that are essentially unrelated with the given instance, can have a critical impact on the relative order of feature importance. Whereas formal explanations and adversarial examples have a precise logic-based formalization, for the two example DTs (and also for the boolean classifiers discussed later in this article), there is no apparent logical justification for the relative feature importance obtained with SHAP scores.
We refer to the misleading information produced by SHAP scores as an example of an issue that can be formalized as follows:
(22)
The logic statement above may appear as rather specific, and so difficult to satisfy, because every feature must either be relevant and be assigned a zero SHAP score, or otherwise it must be irrelevant and be assigned a non-zero SHAP score. However, the example DT in Figure 1a shows that there are very simple classifiers with instances that satisfy the logic statement. Clearly, many other similarly simple examples could be devised. As we will clarify, Equation (22) is referred to as issue I8.
Revisiting the hypothetical scenario. We consider again the instance , that is, an honors student from an urban household and majoring in sciences will enroll for 1 extra-curricular activity, for both DTs. Given the DTs or the TRs, formal explanations would deem the fact that she is an honors student as the answer to why the prediction is one extra-curricular activity. Also, to change the prediction, we would have to consider a non-honors student. Finally, to predict something other than 1 activity, while minimizing changes, then we would once again have to consider a non-honors student. Unsurprisingly, for the second DT (see Figure 1c), SHAP scores concur with assigning the most importance to the fact that the student is an honors student, even though SHAP scores assign some clearly unjustified importance to the other features. More unsettling, for the first DT (see Figure 1a), SHAP scores assign importance to the fact that the student is majoring in science, that she hails from an urban household, but entirely ignore the fact that she is an honors student. And the differences between the two DTs are only the number of extra-curricular activities of non-honors students who major in arts. The reason for this abrupt change in relative feature importance (that is, 1,3,2 to 3,2,1) is inscrutable.
More Issues with SHAP Scores
By automating the analysis of boolean functions,13 we identified a number of issues with SHAP scores for explainability, all of which illustrate how SHAP scores can provide misleading information about the relative importance of features. The choice of boolean functions as classifiers is justified by the computational overhead involved in enumerating functions and their ranges. The list of possible issues is summarized in Table 5. Issue I8 was discussed above and its occurrence implies the occurrence of several other issues. Our goal is to uncover some of the problems that the use of SHAP scores for explainability can induce, and so different issues aim to highlight such problems.
Table 5. Identified potential issues with SHAP scores. (I5 denotes I5 with replaced by .)
Table 5. Identified potential issues with SHAP scores. (I5 denotes I5 with replaced by .)
Table 6 summarizes the percentage of functions exhibiting the identified issues, and it is obtained by analyzing all of the possible boolean functions defined on four variables. For each possible function, the truth table for the function serves as the basis for the computation of all explanations, for deciding feature (ir)relevancy, and for the computation of SHAP scores. The algorithms used are detailed in earlier work,13 and all run in polynomial-time on the size of the truth table. For example, whereas issue I5 occurs in 1.9% of the functions, issues I1, I2 and I6 occur in more than 55% of the functions, with I1 occurring in more than 99% of the functions. It should be noted that the identified issues were distributed evenly for instances where the prediction takes value 0 and instances where the prediction takes value 1. Also, the two constant functions were not accounted for. Moreover, it is the case that no boolean classifier with four features exhibits issue I8. However, as the earlier sections highlight, there are discrete classifiers, with three features of which only one is non-boolean, that exhibit issue I8. The point here is that one should expect similar unsettling issues as the domains and ranges of classifiers increase. Besides the results summarized in this section, additional results14 include proving the existence of arbitrary many boolean classifiers for which issues I1 to I7 occur. Furthermore, more recent work demonstrates the occurrences of some of these issues in practical classifiers, including decision trees and decision graphs represented with ordered multi-valued decision diagrams.15
Table 6. Results over all 4-variable boolean functions. The two constant functions were discarded, since is required not to be constant. Issue I8 is not reported, because there are no occurrences.
Table 6. Results over all 4-variable boolean functions. The two constant functions were discarded, since is required not to be constant. Issue I8 is not reported, because there are no occurrences.
Why do SHAP scores mislead? We identified two reasons that justify why SHAP scores can provide misleading information: the contributions of all possible subsets of fixed features are considered; and class values are explicitly accounted for. For the examples studied in this article, these two reasons suffice to force SHAP scores to provide misleading information.
Discussion
This article demonstrates that there exist very simple classifiers for which SHAP scores produce misleading information about relative feature importance, that is, features bearing some influence on a predicted class (or even determining the class) can be assigned a SHAP score of 0, and features bearing no influence on a predicted class can be assigned non-zero SHAP scores. In such situations there is a clear disagreement between the stated meaning of feature importance ascribed to SHAP scores23,37,38 and the actual influence of features in predictions. It is plain that in such situations human decision-makers may assign prediction importance to irrelevant features and may overlook critical features. The results in this article are further supported by a number of recent results, obtained on arbitrary many classifiers,13,14 that further confirm the existence of different issues with SHAP scores, all of which can serve to mislead human decision makers.
Furthermore, the situation in practice is bleaker than what these statements might suggest. For classifiers with larger number of features, recent experimental evidence suggests close to no correlation between the measures of feature importance obtained with tools like SHAP and those determined by rigorous computation of SHAP scores.13 It would be rather unexpected that tools that fail to approximate what they aim to would in turn obtain more accurate measures of feature importance. A final practical remark of the results in this article is that the continued practical use of tools that approximate SHAP scores should be a reason of concern in high-risk and safety-critical domains. Recent work proposes alternatives to the use of SHAP scores.13,40
Acknowledgments
This work was supported by the AI Interdisciplinary Institute ANITI, funded by the French program “Investing for the Future—PIA3” under Grant agreement no. ANR-19-PI3A-0004, and by the H2020-ICT38 project COALA “Cognitive Assisted agile manufacturing for a Labor force supported by trustworthy Artificial intelligence.” This work was motivated in part by discussions with several colleagues including L. Bertossi, A. Ignatiev, N. Narodytska, M. Cooper, Y. Izza, O. Létoffé, R. Passos, A. Morgado, J. Planes and N. Asher. Joao Marques-Silva also acknowledges the extra incentive provided by the ERC in not funding this research.
Joao Marques-Silva was with IRIT, CNRS in Toulouse, France. He is now Research Professor at ICREA, University of Lleida, Spain.
Xuanxiang Huang was with the University of Toulouse, France. He is now a postdoctoral researcher with CNRS@CREATE, Singapore.
Footnotes
a
Given the many envisioned applications of ML, our claim is that explainability is a topic of such importance that it should not be gambled upon. The main conclusion to draw from our work is that the existing foundations of SHAP scores must be revised.
b
A classifier that computes a constant function, that is, the same prediction for all points in feature space, is uninteresting, and so it is explicitly disallowed.
c
It would be fairly straightforward to create two datasets, for example, the two TRs shown, from which the DTs shown in Figures 1a and 1c would be induced using existing tree learning tools.
d
When defining concepts, we will show the necessary parameterizations. However, in later uses, those parameterizations will be omitted, for simplicity.
e
It should be noted that feature relevancy is tightly related with the concept of relevancy studied in logic-based abduction.10
References
[1]
Arenas, M., Barceló, P., Bertossi, L.E., and Monet, M. The tractability of SHAP-score-based explanations for classification over deterministic and decomposable boolean circuits. In AAAI, 2021, 6670–6678.
Arenas, M. et al. On the complexity of SHAP-score-based explanations: Tractability via knowledge compilation and non-approximability results. J. Mach. Learn. Res. 24, (2023), 63:1–63:58; http://jmlr.org/papers/v24/21-0389.html
Chen, H., Covert, I.C., Lundberg, S.M., and Lee, S. Algorithms to estimate shapley value feature attributions. CoRR abs/2207.07605, 2022; arXiv:2207.07605
Datta, A., Sen, S., and Zick, Y. Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems. In IEEE S&P, 2016, 598–617.
Kumar, E., Venkatasubramanian, S., Scheidegger, C., and Friedler, S.A. Problems with shapley-value-based explanations as feature importance measures. ICML, 2020, 5491–5500.
Lipovetsky, S. and Conklin, M. Analysis of regression in game theory approach. Applied Stochastic Models in Business and Industry 17, 4 (2001), 319–330.
Strumbelj, E. and Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 41, 3 (2014), 647–665;
The alarming growth rate in the online game industry calls for a need of understanding the determinants of online gamers’ behaviour. Investigating how online gamers choose different online characters assists online game vendors to design characters that ...
Psychological factors impact gameful experience and the attitudes of online gamers.
Abstract
Gamification on the mobile platform through the concept of online games has the potential to create unprecedented engagement with customers. With the growth in the gamification market due to the increase in internet penetration and the ...
Computer games have become a highly popular form of entertainment and have had a large impact on how University students spend their leisure time. Due to their highly motivating properties computer games have come to the attention of educationalists who ...
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
 Joao Marques-Silva and
Joao Marques-Silva and